There are several tools on the market for data analysis, from the most complex to the simplest to use. The aim of this series of discussions will be to dispel some myths about the real need to use supercomputers to achieve more accurate results than can be done with a 99-1 combination, that is, by leaving 99% of the work to the computer and the 1% to human common sense.
Allow me to indulge my nostalgic weakness and to report short historical notes on Machine Learning. It all began between 1763 and 1812, when Bayes’ theorem was formulated, which first explained how to minimize the classification error by minimizing the probability of occurrence of an event conditioned by a set of attributes.
Then the silence for about a century, up to Markov, that many will know, if only because seen in the design of telecommunications networks and much more, including the analysis of texts and natural language.
Then for another half century another silence; meanwhile the greatest scientist of the era, Alan Turing, was working on the “war”. But at the end of this dark period, he gave life to what will be the foundation of the analysis of the data in modern key: neural networks. In those years, the production of transistors on an industrial scale and the consequent increase in the computational capabilities of computers made it possible to implement most of the algorithms deriving from game theory. It is no coincidence that one of the main pitfalls of computer designers of the last century was to be able to beat the chess world champions. And IBM did it for the first time in 1996.
But let’s get back to us, precisely in the 70s, when the foundations were laid for the backpropagation algorithms that have evolved up to the present day in the Generative Adversarial Networks (GANs). By the way, I strongly advise you to read the contents of the MIT website which explains the basics of what is most advanced today in the field of research: http://introtodeeplearning.com/, especially as regards the generation of the so-called “Deep Fake” . If you want to know, for example, which of these faces is real and which is artificially generated, go to the indicated link and find out.

Finally, the news of the experimentation in the context of the Sync project, which has created the prototype of an elementary hybrid network of three neurons, one biological and two artificial, in the field of Bio Medicine, is just these days.
If you have already done so and you are updated and aware, you will have wondered what the ethical limit is for all these applications. Right now I don’t have an answer, but a suggestion: there is a way to deceive the calculators and it is contained in the link above.
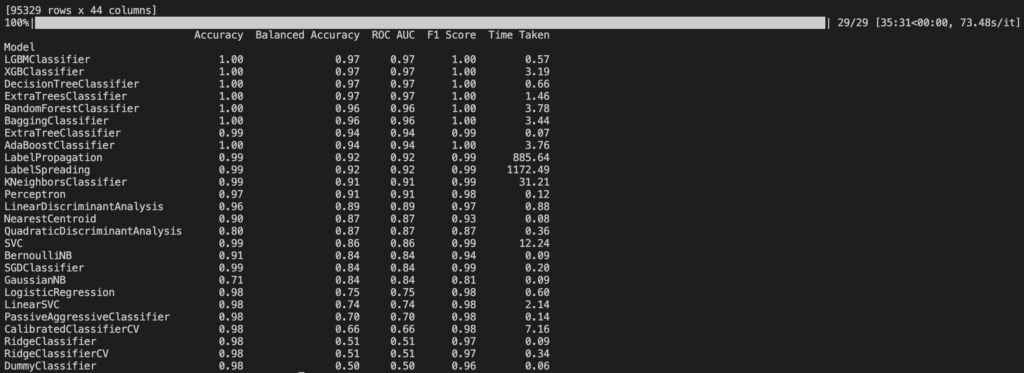
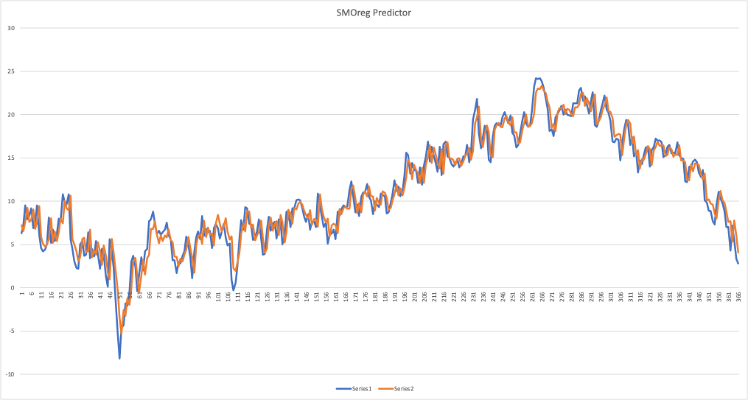
Let’s go back to our goal: is it really useful to apply stacking and voting to our learning algorithm? Before expressing an evaluation and some experimental results, let’s remember the definitions. Stacking is the combination of several models in succession to improve the results of machine learning, while voting and averaging are two ensemble methods: voting is used for classification and the average is used for regression and in practice they select the value. of the target variable (both for classification and for prediction) based on the greater number of votes expressed by the algorithms used.
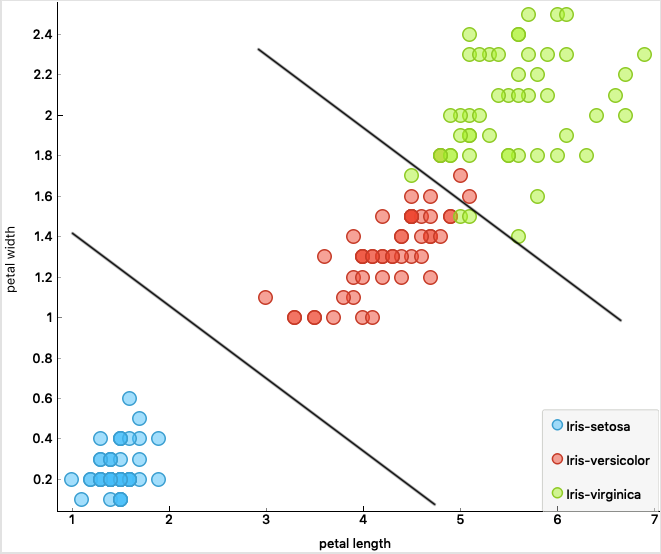
Attributes: width and length petal and sepal ; 150 instances
A good mathematician would answer this question: “it depends on the input data”, and therefore we follow the same procedure. Before starting, however, let’s summarize what is the problem of classification and, therefore, of prediction. And let’s start from the first and most famous public domain dataset: Iris, dated 1936, which describes a set of Iris flowers of three different species, which therefore have individually different characteristics according to four parameters.
The classification can take place, for example, by defining a “boundary” that can separate the blue samples (the choice of the noun is not accidental), that is iris-silky from iris-versicolor and iris-virginica. In this case a linear border manages to separate the samples quite well and there are only a few “exceptions” or outliers. However, we will always ask ourselves later: is it better to increase the complexity of the model to identify and correct classification errors or do those samples represent exceptions and is it better to focus on why such exceptions occur? If we call these exceptions, or anomalies, for example, with the name “Spam” or “Cyber Attack” we will understand why this is one of the main problems of IT at the moment. If we are good at classifying instances (events), we are also good at predicting the future, or simply at understanding the event better. In the example we have seen, the Adaboost and Random Forest algorithms lead to an accuracy of 97.9%, which means that given an Iris represented only by the four attributes, petal width, petal length, sepal width, sepal length , we can predict with what 97.9% accuracy what type of Iris it is, without seeing it. But without forgetting that that will be a new sample for my dataset (Knowledge Base). Of course we could do the same thing in many different areas, for example trying to predict the quality of a wine based on some attributes such as PH, residual sugar, citric acid, sulphates, etc., without tasting it.
Let’s go back to our models and represent from the side just an example of a stacking model for the evaluation of the classification accuracy starting from data of different nature, both playing with datasets. There are 497 available at this address: https://archive.ics.uci.edu/ml/datasets.php or you can access the European Open Data portal: https://data.europa.eu/euodp/it/ date/
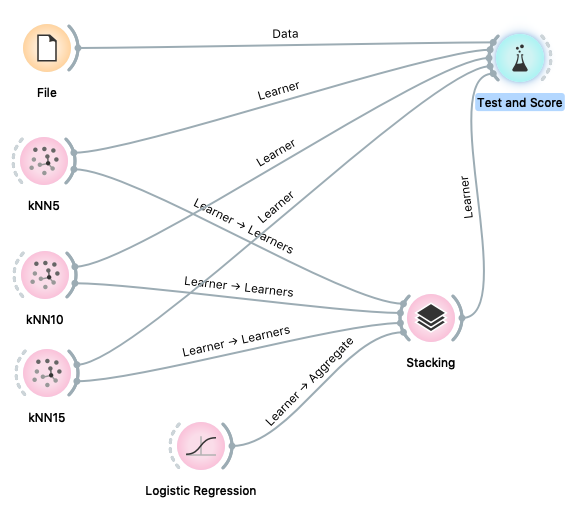
Stacking Model with KNN5, 10 and 15
Zoo animals: dataset size 101 instances, 16 attributes
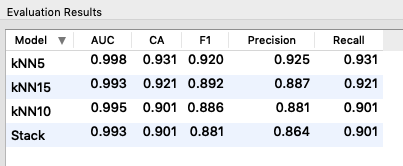
By injecting different datasets into the model, we find that, in most cases, stacking does not improve the precision of the algorithm used individually, therefore we can say that the goodness of the methodology depends not only on the input data but also on the type of data itself.
With elementary procedure it can be demonstrated, even in the case of voting, that preferring the most accurate model leads to higher accuracy than relying on the results obtained by the majority of the algorithms used, especially for the identification of anomalies.
Another matter, however, the methodologies used in the Convolutional Neural Networks (CNN), for example, for the recognition of images, which break the problem into different sub-problems and cascade different algorithms to these different sub-problems (see 6S191_MIT_DeepLearning_L3) .
I close this article in the hope of not having bored the more experienced, nor of discouraging the new “followers”; however, the areas of expertise embraced are numerous and I am sure that each of you will find a field of application for data analysis. And we will also see some code and algorithms in the next articles.
G. Fruscio